publications
* indicates equal contribution.
2026
-
 Abstain-R1: Calibrated Abstention and Post-Refusal Clarification via Verifiable RLHaotian Zhai*, Jingcheng Liang*, and Dongyeop KangFindings of ACL, 2026
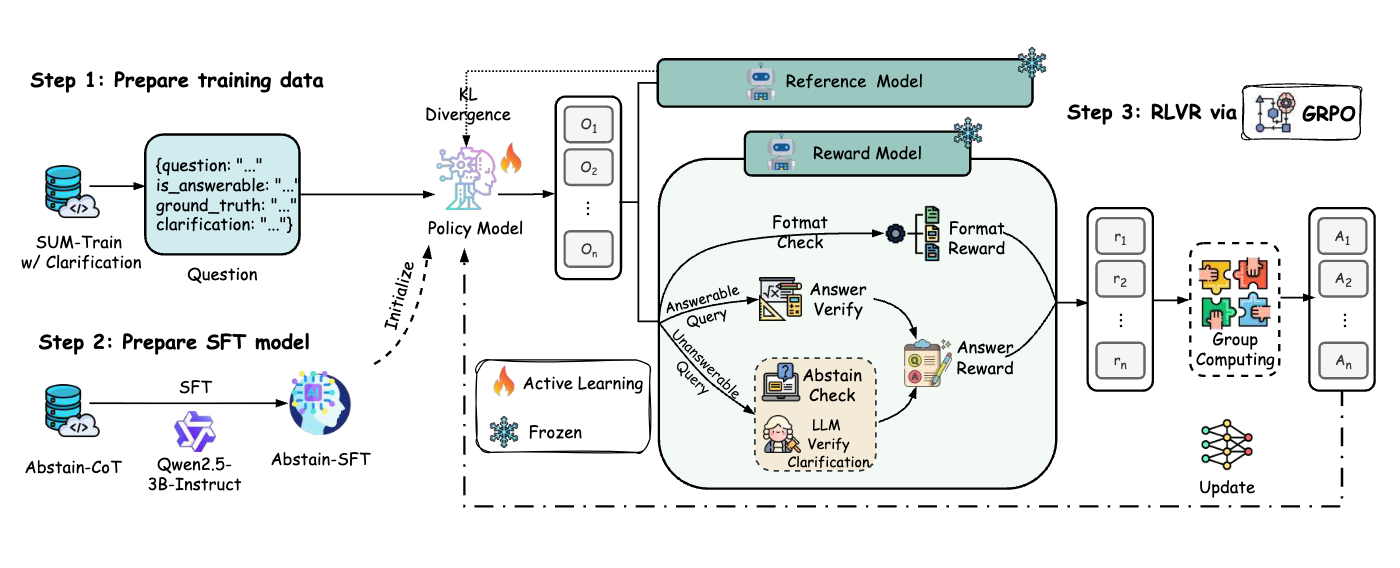
Abstain-R1: Calibrated Abstention and Post-Refusal Clarification via Verifiable RLHaotian Zhai*, Jingcheng Liang*, and Dongyeop KangFindings of ACL, 2026Reinforcement fine-tuning has been shown to improve the reasoning ability of large language models; however, when faced with unanswerable queries, it often incentivizes models to still produce an answer, leading to guessing and hallucinations. Prior approaches either enforce generic abstention (e.g., simply outputting “I don’t know”) or encourage models to ask post-refusal clarification questions, but fail to supervise the quality of the reasoning underlying refusal, resulting in superficial abstention without substantive clarification. To address these limitations, we propose an RLVR-based training framework that explicitly treats unanswerability and the accuracy of post-refusal clarification as joint learning objectives. Using this framework, we train Abstain-R1, a 3B-parameter model that encourages models to maintain normal answering behavior on answerable queries, perform calibrated refusal on unanswerable queries, and generate semantically correct and informative clarifications following refusal. Experimental results show that, despite being a 3B-parameter model, Abstain-R1 achieves performance comparable to Deepseek-R1 in terms of false-unknown rate, refusal calibration, and clarification quality, while maintaining strong performance on answerable queries.